Tidy tools for
supporting fluent workflow
in temporal data analysis
Earo Wang
What is (temporal) data analysis?
What is data analysis? and what is temporal data analysis.
Data analysis is a process of inspecting, cleansing, transforming, and modeling data with the goal of discovering useful information, informing conclusions, and supporting decision-making.
--- Wikipedia
There is a great amount of variation in defining what is a data analysis. According to Wikipedia, data analysis is a process: inspecting, cleansing, transforming, and modelling. And out of this process, we'll learn some knowledge and insights from the data, and make some decisions.
Temporal data analysis is a process of inspecting, cleansing, transforming, and modeling time-indexed data with the goal of discovering useful information, informing conclusions, and supporting decision-making related to time.
--- EaroWiki
How about temporal data analysis? We still go through the same process, but the data dealt with is time-indexed data. The decisions we're going to make are somehow related to time.
But in order to conduct this process and analyse the data, we need tools. There are many tools out there. We have to carefully choose the good ones to lubricate this process as smoothly as possible. This set of tools, we call them "tidy tools".
What are messy tools?
Before introducing you tidy tools, I'd like to show you an example of what messy tools are.
2018
ETC3550: Applied forecasting
This is a slide that I took from last year's Applied forecasting unit taught by Rob. I'm going say this is the messy tools' example. (Sorry, Rob)
It's about fitting three regressions on one data set but with different time trends as regressors. The first two code blocks are straightforward: the first one is linear trend and then forecast 10 steps ahead; the second is exponential trend by taking a log transformation on the response variable but using lambda = 0 and then forecast.
But the third one looks a bit horrified, many new functions have been introduced. The actual idea is simple, fitting a piecewise linear trend. Clearly this tslm() doesn't incorporate the piecewise case. So both the lecturer and the students get distracted from the modelling idea but have to understand how to implement the algorithm first. More importantly, this piece of code is very ad hoc. A few tweaks needed for a different data set, and there's possibility to invite mistakes while tweaking.
🤔 Should all forecasting students be programmers?
This makes me wonder if students should become programmers first before they can become forecasters.
🤔 Should all forecasting students be programmers?
Definitely not!
They do have to know how to program to do data analysis. But they don't have to be programmers. Particularly it's not the purpose of that unit.
Now I hope you get a sense of what are messy tools. In terms of sensation, messy tools are smelly.
What are messy tidy tools?
Contrasting to messy tools, they are tidy tools.
2019
ETC3550: Applied forecasting
This year, Rob is going to teach the same materials but use a different set of tools. You can see the code is clean and succinct.
Most importantly, it helps to communicate the modelling idea in a very clear way. We are going to model this data with three linear regressions. It also addresses the difference between piecewise and a linear trend is by adding knots. Once we're done with model fitting, we forecast them as a whole.
What has been abstracted away is computational implementations and put more emphasis on ideas and expressions. It makes teaching easier and more fun. The door for introducing mistakes is closed. This set of tools are "tidy tools". (Good job, Rob)
- Tidy tools are accessible.
- Tidy tools are expressive.
- Tidy tools are pipeable.
marathon %>% model( linear = TSLM(Minutes ~ trend()), exponential = TSLM(log(Minutes) ~ trend()), piecewise = TSLM(Minutes ~ trend(knots = c(1940, 1980))) ) %>% forecast(h = 10)This is my conceptualisation about "tidy tools":
- Tidy tools are accessible. It means anyone can run this bit of code, anywhere anytime, to produce identical results. There shouldn't be a paywall to prevent users from using it. The source code can be inspected by others as well.
- Tidy tools are expressive. Tidy tools are code, and code is text. We can express our ideas in text and we can frame our data analysis problems through code. Code is documentation, documenting how we approach the problem. We can easily share plain text across different platforms and groups of people. This goes beyond what point and click software can do. Yes, it is R code. But I believe someone who never used R before, they should be able to quickly get what's happening here. This is the power of expressiveness.
- Tidy tools are pipeable. Because the input format is consistent with the output format. We can chain these operations together to build a fluent pipeline and read more naturally. Modelling and then forecasting. It makes possible to have fluent workflow.
What is fluent workflow?

Data analysis is a process, particularly it's an iterative process.
The tidyverse is a collection of R packages to help with this process quick and tidy.
Why it's important? Before deploying the final model into the production stage, we need to repeat this process many many times. If this model doesn't work, we make some tweaks, and then fit another model. We want this iteration as rapid as possible.
In addition to tidy tools, what's underlying this fluent workflow is tidy data.
The "tidy" stage doesn't mean data cleaning, but refers to making the data in a right shape, a uniform shape that is shared by these three stages in this circle.
With the tidyverse, we have such a fluent pipeline to handle data analysis. But when you have time series data and want to do time series analysis ...
Welcome to
time series analysis

WAT!😱
This is what you experience. Lots of you in this department primarily focus on the statistical models. But I have been working on the rest of the process to support modelling.
Small data lives in csv files, big data stays in database. But most time, the form of the data at the "import" stage deviates a lot from the current time series objects that are designed for modelling. When doing transformation and visualisation, different data shapes are expected. We do not have a uniform shape for lubricating this process for time series. There's no formal guidance how to reshape the data for modelling purpose.
Screaming out "WAT" is the natural response to this workflow. Let me share my "WAT" moment.
WAT!😱
# Put them into a big matrixltraffics <- list(as.bf.cpu, as.bf.busy, as.bf.memory, as.bf.page, as.gq.cpu, as.gq.busy, as.gq.memory, as.gq.page, as.ir.cpu, as.ir.busy, as.ir.memory, as.ir.page, ... hs.gq.cpu, hs.gq.busy, hs.gq.memory, hs.gq.page, hs.ir.cpu, hs.ir.busy, hs.ir.memory, hs.ir.page, hs.ne.cpu, hs.ne.busy, hs.ne.memory, hs.ne.page, hs.sg.cpu, hs.sg.busy, hs.sg.memory, hs.sg.page)indcols <- sapply(ltraffics, ncol)cs <- cumsum(c(1, indcols))totalcols <- sum(indcols)traffics <- matrix(, nrow = 719, ncol = totalcols)for (i in 1L:length(ltraffics)) { idx <- cs[i]:(cs[i + 1] - 1L) traffics[, idx] <- as.matrix(ltraffics[[i]][1:719, ])}When I was doing my honours project years agos, I needed to compute a bunch of time series features on yahoo web traffic data.
The script shows I put multiple csvs into a big time series matrix. But it took me a while to understand what past me was doing.
When I revisit this code, I started to realise there's something fundamentally wrong here. Multiple observational units and multiple measurements have been put into one object, which isn't appropriate for the traditional time series structure.
Welcome
to
the tidyverts

Tsibble defines tidy data in temporal context.
So my work is going to smooth out those rough edges, provides a conceptual framework for temporal data analysis, and fill the gap of tidy data in temporal context. We're going to call this new data structure---"tsibble".
You know I'm serious about this work, bc it has a logo.
Next I'm going to demonstrate this whole data process with tsibble and showcase the value of it.
Temporal data analysis
doesn't make sense
without time-indexed data.
Data analysis cannot live w/o data.
I'm going to share with you two data stories simultaneously.
The LHS is daily users visiting my personal website
Web traffic
#> # A tibble: 1,100 x 2#> Date Users#> <date> <dbl>#> 1 2016-03-22 0#> 2 2016-03-23 0#> 3 2016-03-24 0#> 4 2016-03-25 0#> 5 2016-03-26 0#> 6 2016-03-27 0#> # … with 1,094 more rowsAirline traffic
#> # A tibble: 5,548,445 x 22#> flight_num sched_dep_datetime #> <chr> <dttm> #> 1 AA494 2017-01-17 16:19:00#> 2 AA494 2017-01-18 16:19:00#> 3 AA494 2017-01-19 16:19:00#> 4 AA494 2017-01-20 16:19:00#> 5 AA494 2017-01-21 16:19:00#> 6 AA494 2017-01-22 16:19:00#> # … with 5.548e+06 more rows, and 20#> # more variables:#> # sched_arr_datetime <dttm>,#> # dep_delay <dbl>, arr_delay <dbl>,#> # carrier <chr>, tailnum <chr>,#> # origin <chr>, dest <chr>,#> # air_time <dbl>, distance <dbl>,#> # origin_city_name <chr>,#> # origin_state <chr>,#> # dest_city_name <chr>,#> # dest_state <chr>, taxi_out <dbl>,#> # taxi_in <dbl>, carrier_delay <dbl>,#> # weather_delay <dbl>,#> # nas_delay <dbl>,#> # security_delay <dbl>,#> # late_aircraft_delay <dbl>How the data looks like?
My data is quite simple, with 1000 obs and 2 variables. The Date column provides the time context. and how many visitors.
This data starts from the day when I started my PhD until yesterday. It has a sad beginning that nobody visited my website in the early days.
By contrast, airline data contains 5M obs and 22 variables. The sched_dep_datetime column gives the date-times. Other variables include the meta info describing the flights and on-time performance metrics. It is an event data set.
They already arrived in the tidy shape, with clearly defined observations and variables. Now we need to declare them as temporal data using tsibble.
1. Tsibble is
data representation
for tidy temporal data.

Tsibble is a multi-faceted product.
First of all, tsibble represents tidy temporal data.
A tsibble has to be tidy data first. Data is organised in the common rectangular form: each row is an observation; each column holds a variable. But temporal data is more of a contextual data object. So on top of the tidy data, column variables require more meanings: index for time support, key for defining identities over time, and the rest are measurements.
Contextual semantics
1. Index
Time indices provide a contextual basis for temporal data.
- acknowledge the diversity of time representations
- respect time zones
- allow regular/irregular intervals
2. Key
Key identifies observational units recorded over time.
- comprise empty, one or more variables
- known a priori by analysts
- determine unique time indices
Let me elaborate index and key more.
The index variable consists of time indices that provide a contextual basis for temporal data.
A variety of time representations exist in the wild, the common ones you saw before, dates and date-times, as well as intradays and intervals from one time point to another. Tsibble supports all of them, as long as they can be ordered from past to future.
Unlike other time series objects, tsibble respects time zones, will not ignore them and not convert them to UTC.
Temporal data can be regular and irregularly spaced in time. That's why we say tsibble is temporal data instead of time series.
And the key can consist of empty, one or more variables. It is typically known for analysts. Each observational unit in the key, only allows unique time indices.
These features make tsibble a modern re-imagining temporal data.
Declare a tsibble
web_ts <- web %>% as_tsibble( key = id(), index = Date )#> # A tsibble: 1,100 x 2 [1D]#> Date Users#> <date> <dbl>#> 1 2016-03-22 0#> 2 2016-03-23 0#> 3 2016-03-24 0#> 4 2016-03-25 0#> 5 2016-03-26 0#> 6 2016-03-27 0#> # … with 1,094 more rowsCan these two data sets meet the tsibble definition in the first instance?
Since the web traffic is a univariate series, just about me. So the key is empty. And the index is Date.
Now it's a tsibble object with 1 day interval.
Declare a tsibble
web_ts <- web %>% as_tsibble( key = id(), index = Date )#> # A tsibble: 1,100 x 2 [1D]#> Date Users#> <date> <dbl>#> 1 2016-03-22 0#> 2 2016-03-23 0#> 3 2016-03-24 0#> 4 2016-03-25 0#> 5 2016-03-26 0#> 6 2016-03-27 0#> # … with 1,094 more rowsflights_ts <- flights %>% as_tsibble( key = id(flight_num), index = sched_dep_datetime, regular = FALSE )#> Error: A valid tsibble must havedistinct rows identified by key andindex.#> Please use `duplicates()` to checkthe duplicated rows.Oops!
Can these two data sets meet the tsibble definition in the first instance?
Since the web traffic is a univariate series, just about me. So the key is empty. And the index is Date.
Now it's a tsibble object with 1 day interval.
How about the airline data?
From the passenger's point of view, we're interested in flight number at its scheduled departure time. Also it's irregular interval.
After declaring key and index. Oops! We got an error.
The error says: ... and suggests ...
Another way to interpret this error message is that this data may have data quality issue.
duplicates and them
flights %>% duplicates(key = id(flight_num), index = sched_dep_datetime)#> # A tibble: 2 x 22#> flight_num sched_dep_datetime sched_arr_datetime dep_delay arr_delay#> <chr> <dttm> <dttm> <dbl> <dbl>#> 1 NK630 2017-08-03 17:45:00 2017-08-03 21:00:00 140 194#> 2 NK630 2017-08-03 17:45:00 2017-08-03 21:00:00 140 194#> carrier tailnum origin dest air_time distance origin_city_name#> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr> #> 1 NK N601NK LAX DEN 107 862 Los Angeles #> 2 NK N639NK ORD LGA 107 733 Chicago #> # … with 10 more variables: origin_state <chr>, dest_city_name <chr>,#> # dest_state <chr>, taxi_out <dbl>, taxi_in <dbl>, carrier_delay <dbl>,#> # weather_delay <dbl>, nas_delay <dbl>, security_delay <dbl>,#> # late_aircraft_delay <dbl>We need to search for those duplicates and fix them.
As you can see, we've got two problematic entries. The flight number NK630 has been scheduled twice at the same departure time. They have identical arrival time, departure delay, arrival delay, and carrier. But they are different in tail number, origin and destination. After researching this flight number and going through the whole database, my decision is to remove the highlighted entry: the flight from LAX to DEN, bc this flight doesn't operate on this route.
Tsibble is strict on tidy data.
flights_ts <- flights %>% filter(!dup_lgl) %>% as_tsibble( key = id(flight_num), index = sched_dep_datetime, regular = FALSE )#> # A tsibble: 5,548,444 x 22 [!] <UTC>#> # Key: flight_num [22,562]#> flight_num sched_dep_datetime sched_arr_datetime dep_delay#> <chr> <dttm> <dttm> <dbl>#> 1 AA1 2017-01-01 08:00:00 2017-01-01 11:42:00 31#> 2 AA1 2017-01-02 08:00:00 2017-01-02 11:42:00 -3#> 3 AA1 2017-01-03 08:00:00 2017-01-03 11:42:00 -6#> 4 AA1 2017-01-04 08:00:00 2017-01-04 11:42:00 -3#> 5 AA1 2017-01-05 08:00:00 2017-01-05 11:42:00 -7#> 6 AA1 2017-01-06 08:00:00 2017-01-06 11:42:00 -3#> # … with 5.548e+06 more rows, and 18 more variables: arr_delay <dbl>,#> # carrier <chr>, tailnum <chr>, origin <chr>, dest <chr>,#> # air_time <dbl>, distance <dbl>, origin_city_name <chr>,#> # origin_state <chr>, dest_city_name <chr>, dest_state <chr>,#> # taxi_out <dbl>, taxi_in <dbl>, carrier_delay <dbl>,#> # weather_delay <dbl>, nas_delay <dbl>, security_delay <dbl>,#> # late_aircraft_delay <dbl>Once we remove the duplicated observation, we are all good.
Irregular time space is marked by exclamation mark. and we've got 22 thousands of flights or series in the table.

When creating a tsibble object, we're also going through the tidy stage. Tsibble complains early when the data involves duplicates, like the flights data. We need to find the duplicates and fix them. We now end up with a properly-defined temporal data.
Tsibble permits time gaps. It is recommended to check time gaps before transformation and modelling. Bc you are likely to encounter errors if gaps in time. Luckily no gaps in these two data sets.
Tsibble provides formal organisation on how to tidy your temporal data.

In harmony with grammar of graphics
web_ts %>% ggplot(aes(x = Date, y = Users))
Tsibble as a data object, it's also the first time series object that can directly talk to grammar of graphics, without coercion.
The grammar of graphics defines plots as a functional mapping from data points to graphical elements. The plot is initialised through mapping variables from data space to graphical space. Variable Date is mapped to x axis and Users mapped to y axis. But I haven't put the visual elements on the canvas yet. So it's just empty.
In harmony with grammar of graphics
web_ts %>% ggplot(aes(x = Date, y = Users)) + geom_area(colour = "#3182bd", fill = "#9ecae1")
Instead of a line chart, I add an area geom on the canvas with specified colours.
This plot tells my phd life was quiet in the first year. Since May 2017, this website started to attract more or less traffic. It was the time I started to deliver workshops and present to a wider audience. The year of 2018 saw many spikes, because I talked, talked, and talked a lot. It was fun to look at how my phd performs over three years.
2. Tsibble is
a domain specific language in
for wrangling temporal data.
Good fluent APIs take a while to build.
Tsibble is not only a data abstraction, but also a DSL for wrangling temporal data.
Like we can make a plot layer by layer with grammar of graphics, we can chain operation by operation using tsibble to make a complete analysis. Bc the grammar is declarative.
When I actually develop tsibble, I started to appreciate the tidyverse team. Lots of amazing design thinking behind it. A fluent and consistent API gives an intuitive pipeline but it takes lots of time to refine the idea. For example, naminng a thing is difficult.
1. Vector functions
yearmonth()/yearquarter()time_in()difference()
3. Window family
slide()/future_slide()tile()/future_tile()stretch()/future_stretch()
2. Table verbs
scan_gaps()/fill_gaps()index_by()/group_by_key()filter_index()
4. Extend tsibble
index_valid()pull_interval()new_tsibble()
In order to master a language, we need to learn vocabularies first.
The tsibble dictionary divides into 4 major blocks.
- Vector functions deals with 1 dimentional vector, mostly time vector
- Unlike vector functions, table verbs take a data table and returns a data table
- It is necessary to have commonly-used rolling window operations
- Other functions to make tsibble extensible to support new index type and data class.
These functions are written and organised independently to achieve greater flexibility. so users can interweave any of these functions to solve a particular problem. This slide gives you a fraction of vocabularies.
To check out the full list, here it is.
standing on the shoulders of giants
⬢ __ _ __ . ⬡ ⬢ . / /_(_)__/ /_ ___ _____ _______ ___ / __/ / _ / // / |/ / -_) __(_-</ -_)\__/_/\_,_/\_, /|___/\__/_/ /___/\__/ ⬢ . /___/ ⬡ . ⬢If you're familiar with the tidyverse, the learning curve for tsibble is very gentle. Bc tsibble leverages the tidyverse verbs but in a slightly different way.

web %>% select(Users)#> # A tibble: 1,100 x 1#> Users#> <dbl>#> 1 0#> 2 0#> 3 0#> 4 0#> 5 0#> 6 0#> # … with 1,094 more rows
web_ts %>% select(Users)#> Selecting index: "Date"#> # A tsibble: 1,100 x 2 [1D]#> Users Date #> <dbl> <date> #> 1 0 2016-03-22#> 2 0 2016-03-23#> 3 0 2016-03-24#> 4 0 2016-03-25#> 5 0 2016-03-26#> 6 0 2016-03-27#> # … with 1,094 more rowsI'm constrasting how the same verb works differently for a normal data table and a tsibble.
For example, selecting columns from a normal data table, you get a table with that columns.
However, selecting tsibble's columns, it automatically selects the index variable. it always keeps the time context around and will not drop it. Without index and key, a tsibble will no longer be a tsibble.
web %>% summarise(Users = sum(Users))#> # A tibble: 1 x 1#> Users#> <dbl>#> 1 4942
web_ts %>% summarise(Users = sum(Users))#> # A tsibble: 1,100 x 2 [1D]#> Date Users#> <date> <dbl>#> 1 2016-03-22 0#> 2 2016-03-23 0#> 3 2016-03-24 0#> 4 2016-03-25 0#> 5 2016-03-26 0#> 6 2016-03-27 0#> # … with 1,094 more rowsSummarising a table, it reduces to a single value. But summarising a tsibble, it computes the values over time. For this case, it returns itself.
We use the tidyverse verbs to avoid introducing new verbs for less cognitive burden on users. But we give those verbs more contextual meaning so they behave more intuitively in the temporal context.
Compose prose
web_year <- web_ts %>% index_by(Year = year(Date)) %>% summarise(Users = sum(Users))#> # A tsibble: 4 x 2 [1Y]#> Year Users#> <dbl> <dbl>#> 1 2016 163#> 2 2017 1149#> 3 2018 2562#> 4 2019 1068
We gradually build up our vocabularies in order to write a sentence and futher compose prose.
For example, this sentence begins with the data. And an action performed on this data is an adverb plus a verb. This describes this action is aggregating daily data to annual data.
Yearly data makes my story look promising. Visitors doubled every year. The first quarter of this year is almost as the sumup of 2017.
This is a brief sentence with the web traffic.

sel_delay <- flights_ts %>% filter(origin %in% c("JFK", "KOA", "LAX")) %>% group_by(origin) %>% index_by(sched_dep_date = as_date(sched_dep_datetime)) %>% summarise(pct_delay = sum(dep_delay > 15) / n())#> # A tsibble: 1,095 x 3 [1D]#> # Key: origin [3]#> origin sched_dep_date pct_delay#> <chr> <date> <dbl>#> 1 JFK 2017-01-01 0.15 #> 2 JFK 2017-01-02 0.281#> 3 JFK 2017-01-03 0.309#> 4 JFK 2017-01-04 0.15 #> 5 JFK 2017-01-05 0.167#> 6 JFK 2017-01-06 0.279#> # … with 1,089 more rows
A paragraph for airline traffic is made up of two adv and two verbs. Selecting three airports: JFK, Hawaii, and LAX from hundreds of them. and then get a summary of daily percentage delay for each airport.
The airport in Hawaii, is low in delay with better on-time performance all year around.
Once you internalise this set of grammar, all sorts of transformation come handy.
3. Tsibble rolls with
functional programming.
FP focuses on expressions instead of for-loop statements.
The third aspect of tsibble is adopting FP for rolling windows.
When doing rolling window analysis, we cannot avoid for loops. But tsibble's rolling family keeps users away from for loops. and help concentrate on what you're going to achieve instead of how you're going to achieve.
x <- 1:12ma_x1 <- double(length = length(x) - 1)for (i in seq_along(ma_x1)) { ma_x1[i] <- mean(x[i:(i + 1)])}ma_x1#> [1] 1.5 2.5 3.5 4.5 5.5 6.5#> [7] 7.5 8.5 9.5 10.5 11.5mm_x2 <- integer(length = length(x) - 2)for (i in seq_along(mm_x2)) { mm_x2[i] <- median(x[i:(i + 2)])}mm_x2#> [1] 2 3 4 5 6 7 8 9 10 11⬅️ For loops
A toy example: computing moving averages for window size 2 and median for 3
In order to compute the mean and median, I have to do a bit of setup for the loop. But the only part we're interested is the action: mean and median.
The length of output is not stable, depending on the the choice window size. This is for loop
x <- 1:12ma_x1 <- double(length = length(x) - 1)for (i in seq_along(ma_x1)) { ma_x1[i] <- mean(x[i:(i + 1)])}ma_x1#> [1] 1.5 2.5 3.5 4.5 5.5 6.5#> [7] 7.5 8.5 9.5 10.5 11.5mm_x2 <- integer(length = length(x) - 2)for (i in seq_along(mm_x2)) { mm_x2[i] <- median(x[i:(i + 2)])}mm_x2#> [1] 2 3 4 5 6 7 8 9 10 11slide_dbl(x, mean, .size = 2)#> [1] NA 1.5 2.5 3.5 4.5 5.5#> [7] 6.5 7.5 8.5 9.5 10.5 11.5slide_int(x, median, .size = 3)#> [1] NA NA 2 3 4 5 6 7 8 9#> [11] 10 11⬆️ Functionals
What I mean by FP? It abstracts away the for-loop, and focus on what you want to do by supplying a function. And it's length-stable and type-stable.
🕵️♀️
👩💻
👩🔬
👩🎨
👩🚒
👩🚀
🦸♀️
🧙♀️
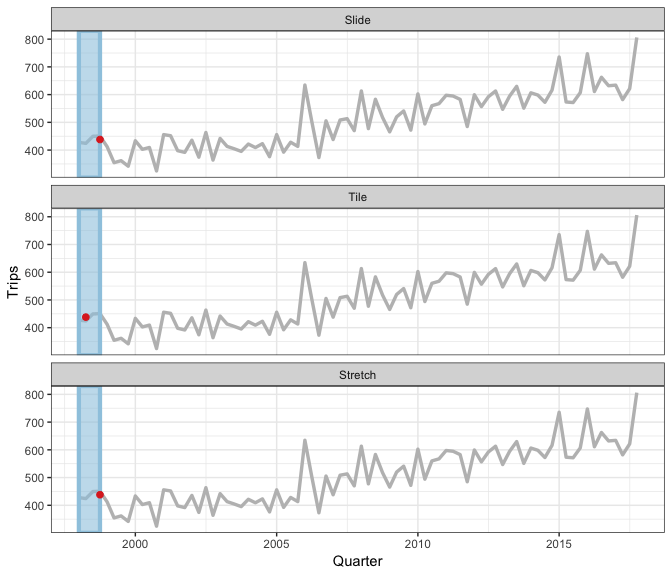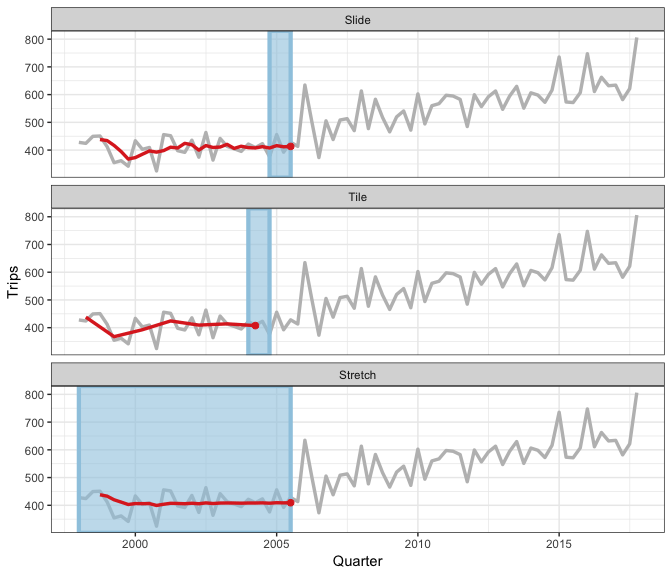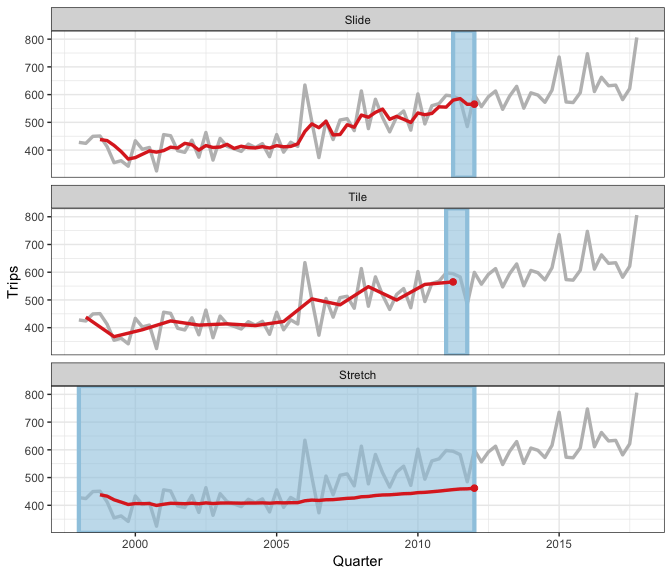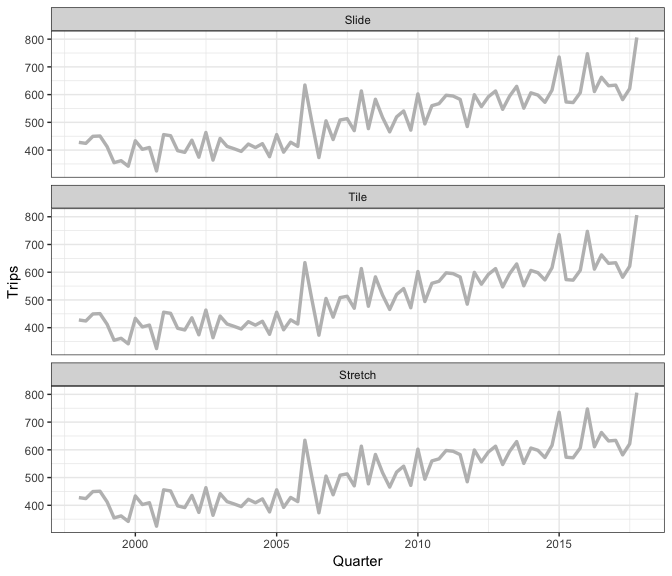
Rolling window animation
- as simple as moving average calculation
- as complex as rolling model fitting
- useful for time series cross validation
- allow arbitrary types of inputs & outputs
- support parallel processing
3 types of rolling window
- sliding: moves a fixed length window through the data with overlapping
- tiling: moves a fixed length window through the data w/o overlapping
- stretching: fix an initial window and expand to include more observations.
The animation shows three different rolling averages.
it takes an arbitrary function: simple complex
time series CV: easier to compute forecasting accuracy by comparing rolling forecast with rolling data
...
The only limit for how to use this family for window-related analysis is your imagination.

The future is just around the corner.
Last year, I said tsibble was going to be the future of time series. This year, I would say the future is around the corner. A few dependent packages have been developed around the tsibble structure, including the new fable package for forecasting to replace the forecast package. Rob has already started teaching this set of cutting-edge tools in his class this semester. The next generation of forecasters will be more productive.
Takeaway
Tsibble provides
fundamental computing infrastructure.
What's my contribution is:
Tsibble provides a uniform and standardized temporal data structure for downstream analytic tasks. You can easily transform, visualise and model your temporal data, and smoothly shifts between them for rapid iteration to gain data insights.
Tsibble also provides a descriptive grammar that you can express your temporal data analysis problem easily.
Lemme show you a final example to conclude this part by chaining these 3 parts together.
# transformweb_mth <- web_ts %>% index_by(YearMonth = yearmonth(Date)) %>% summarise(Users = sum(Users))# model and forecastweb_fcast <- web_mth %>% model(ets = ETS(Users)) %>% forecast(h = 9) %>% mutate(type = "forecast")# visualiseweb_mth %>% mutate(type = "data") %>% rbind(web_fcast) %>% group_by(type) %>% index_by(Year = year(YearMonth)) %>% summarise(Users = sum(Users)) %>% mutate(type = fct_rev(type)) %>% ggplot(aes(x = Year, y = Users)) + geom_col(aes(fill = type))
Where am I heading?

I'm interested in my website traffic performance in the rest of the year.
3 paragraphs here:
- summarising daily to monthly data, shorten this long series
- fit an ETS and forecast 9 months ahead
- bind historical data and forecast together and aggregate to yearly data.
Xkcd man tells I've got 3000 users to achieve, so pressure is on.
I hope this pipeline looks intuitive to me.
How others think?
I'm in awe of @earowang's
— Miles McBain (@MilesMcBain) December 23, 2018tsibblepackage. Intuitive time series verbage for tidyverse pipelines. Tonight it is eating up tweet summarisation: #rstats pic.twitter.com/Ji5FGZFxfn
At #RStudioConf @earowang tells us about fables, mables and tsibbles. I feel like I’m in an alternate universe where everything is easy with time series. 🧚♂️ pic.twitter.com/fNir8ARlS0
— Laura Ellis (@LittleMissData) January 17, 2019
Calendar-based graphics
Revision and resubmission for JCGS
Tsibble forms the second chapter, and it is submitted to JCGS.
One step backward is the first chapter on calendar-based graphics. It is tentatively accepted by JCGS, asking for revision and resubmission.
Inspired by calendar
Return
to
calendar

The calendar plot is inspired by the actual calendar. You mark your daily schedule on this calendar, and we draw glyphs instead. Interestingly, the function that I wrote for the calendar plot also makes this physical copy of the calendar for our numbats group. So it returns to the calendar.
Calendar layout

The hard work is to layout the panels in the calendar format.
- is to determine what's the weekday that the first day of the month starts, and use modulus arithimetis to figure out the rest. The calendar conforms to 5 rows by 7 columns. The days that exceed the 5th week are wrapped to the first top rows.
Once the layout is setup, the plot drops in.
Calendar plot

Showcase
Everyday running path

Auckland bus delay

User cases by others
- a runner
Missingness in time
Work in progress
One step forward is exploring missing patterns for time series. Many works have been done on missing data, but few for time series. With the support from tsibble, we can better handle temporal missing values from the data-centric point of view.
Types
of
missings in time

We have grouped types of missings into 4 groups.
Missingness in time
- Process for generating missing data in time
- Tools for exploring temporal patterns of missingness
- Assessing results of imputation techniques
- Case study
🌟 Impact
It's generally difficult to measure the research impact. But I've got 2 R pkgs associated with each chapter. Using the pkg metrics could be good proxy.
sugrrants
🥇 2018 Best student paper award from ASA Section on Statistical Graphics
tsibble
🏆 2019 John Chambers Statistical Software Award from ASA Section on Statistical Computing
Total downloads, as of 2019-03-26

📖 Research compendium
A form of publication contains all data and software for better reproducibility, besides the text and figures.
Marwick et al. (2018) peerj.com/preprints/3192
Finally I'd like to share with you some of my thoughts on organising a thesis. I learned this term RC at this year's rstudio conference.
- is a container contains the document and its computations (i.e. text, code, data,...) making code and data available is equally important as text and figures.
- provides a way for distributing, managing and updating the collection.
In this peerj paper, Ben Marwick discusses RC provides a standard and easily recognisable way for organising the digital materials of a research project for better transparency and reproducibility.
I think it's a brilliant idea. I've been practicing it for the thesis.
#> levelName#> 1 . #> 2 ¦--DESCRIPION # Lists of packages used for thesis #> 3 ¦--README.md # Instructions on package's installation and etc.#> 4 ¦--scripts/ # R code for analysis #> 5 ¦--R/ # Reusable R functions #> 6 ¦--Rmd/ # R Markdown for thesis document #> 7 ¦--data/ # Cleaned data used for thesis document #> 8 ¦--data-raw/ # Raw data and scripts to clean data #> 9 ¦--Dockerfile #> 10 °--...earowang/thesis
Persistent reproducibility
It turns out the R pkg structure is well suited for organising research project, if you're using R for analysis.
❤️
 Di
Di
 Rob
Rob
 Heike
Heike
 Mitch
Mitch
 Stuart
Stuart
 David
David
 Roger
Roger
 NUMBATs
NUMBATs
 community
community