A new tidy data structure
to support exploration and modeling of temporal data
Earo Wang
Monash University

In short, I just introduce an R package for tidy temporal data analysis.


Since I'm talking about data analysis in R, I cannot avoid talking about the tidyverse.
This diagram, you probably see it many times, resonates well with data scientists, because it points out the critical steps and the iterative nature of the analysis process.
You can find one of the tidyverse packages correspond to each of the modules here. The tidyverse basically helps with data analysis tidy and smooth in general.
But what this diagram doesn't tell you is they all share the same underlying data structure.
This "tidy" stage doesn't mean data cleaning, but actually means making the data in a right shape, a uniform shape that forms the basis for these three modules in this loop. Now, this kind of data shape is called "tidy data".
With the tidyverse, we have such a fluent pipeline to handle data analysis. But if you have ever done time series analysis in R, I hope this diagram resonates with you well ...
time series verse

WAT!😱
It is a messy-verse.
There are a few time series data classes in R, but all are designed purely for the modelling purpose, which means the object can be quite different from the data at the "import" stage. How to convert the raw data to model objects happen under the table. No formal and transparent organisation is provided on how to reshape the data for modelling, you'll go through such a lumpy path with luck.
Once the data is in the modelling shape, transformation and plotting are doable but not that tidy.
But this diagram only captures the workflow for relatively simple data set. If the data is more complex, for example, many series and many measurements, the diagram doesn't emphasize the difficulty enough.
This motivates the tsibble package that I'm going to talk about.
tidyverts

Tsibble defines tidier data for temporal analysis.
The goal of the tsibble package is to define tidy data in terms of temporal contexts, that is suitable for downstream analysis, like modeling or forecasting, and reduces the friction between data and models. It turns out tsibble is tidier than tidy data. I'll explain what I mean by tidier data later.
Tsibble alone can't do everything in this whole process. A broader picture here is we hope to tidy the time series workflow through the tidyverts ecosystem.
1. Tsibble is
a data abstraction
for tidy temporal data.

What can tsibble do?
First of all, tsibble represents tidy temporal data.
A tsibble is first built on top of the tidy data principles. Tidy data is organised in the rectangular format: each observation forms a row; each variable forms a column. But temporal data is more of a contextual data object. We have introduced index and key to make the temporal context explicit. And the rest of the columns are measurements. But still this figure just describes the shape of a tsibble.
In tsibble:
- Index is a variable with inherent ordering from past to present.
- Key is a set of variables that define observational units over time.
- Each observation should be uniquely identified by index and key.
- Each observational unit should be measured at a common interval, if regularly spaced.
Tsibble is an explicit data- and model-oriented object.
I said before tsibble is a tidier data, because
- The index variable provides a contextual basis for temporal data. Tsibble supports the common ones: dates and date-times, and others like intradays or numbers. Custom time classes can also be supported, as long as they can be ordered from past to future.
- For example, if you're doing survey studies, the participants are the observational units forming the key. Or if you're looking at monthly energy use of households, the households form the key.
- In other words, an observational unit can't allow for duplicated time stamps.
The 1st and 2nd bullet points make tsibble a data-centric object. And the 3rd and 4th make sure it can be probably analysed and modeled later.
Okay, how would these four points turn a data set into a tsibble. Time for tying some R code.
🛫 🌎 🛬
#> # A tibble: 5,548,445 x 22#> flight_num sched_dep_datetime sched_arr_datetime #> <chr> <dttm> <dttm> #> 1 AA494 2017-01-17 16:19:00 2017-01-17 18:56:00#> 2 AA494 2017-01-18 16:19:00 2017-01-18 18:56:00#> 3 AA494 2017-01-19 16:19:00 2017-01-19 18:56:00#> 4 AA494 2017-01-20 16:19:00 2017-01-20 18:56:00#> 5 AA494 2017-01-21 16:19:00 2017-01-21 18:56:00#> 6 AA494 2017-01-22 16:19:00 2017-01-22 18:56:00#> # … with 5.548e+06 more rows, and 19 more variables:#> # dep_delay <dbl>, arr_delay <dbl>, carrier <chr>,#> # tailnum <chr>, origin <chr>, dest <chr>,#> # air_time <dbl>, distance <dbl>, origin_city_name <chr>,#> # origin_state <chr>, dest_city_name <chr>,#> # dest_state <chr>, taxi_out <dbl>, taxi_in <dbl>,#> # carrier_delay <dbl>, weather_delay <dbl>,#> # nas_delay <dbl>, security_delay <dbl>,#> # late_aircraft_delay <dbl>The data set we're looking at is the on-time performance for domestic flights in the States. It's the same data source as the package nycflights13, but it's much bigger, not limited to NYC and also more recent. It's about 2017.
It's a medium-sized data set with 5M obs and 22 variables. (briefly describe the data)
It already arrives as tidy data, with clearly defined observations and variables. Now we need to declare them as temporal data using tsibble.
Declare a tsibble
flights_ts <- flights %>% as_tsibble(key = flight_num, index = sched_dep_datetime, regular = FALSE)click me!
#> A valid tsibble must have distinct rows identified by key and index.#> Please use `duplicates()` to check the duplicated rows.Declare a tsibble
flights_ts <- flights %>% as_tsibble(key = flight_num, index = sched_dep_datetime, regular = FALSE)click me!
#> A valid tsibble must have distinct rows identified by key and index.#> Please use `duplicates()` to check the duplicated rows.duplicates
flights %>% duplicates(key = flight_num, index = sched_dep_datetime)There could a few ways to define the key, depending on the perspective. But from the passenger's point of view, we're interested in flight number at its scheduled departure time. So key = ?, and index = ?. Because it's event data with irregular interval, we have to specify regular = FALSE.
Everything looks good to me. Finger crossed.
Oops! We got an error.
The error says: ... and suggests ...
Another way to interpret this error message is that the data set may have data quality issue. Not every data is our beloved iris data set, small and clean. Especially large data sets need somewhat cleaning. Btw, Di Cook will be talking about the history of iris data on Tuesday.
We need to search for those duplicates and hopefully fix them.
#> # A tibble: 2 x 22#> flight_num sched_dep_datetime sched_arr_datetime dep_delay arr_delay#> <chr> <dttm> <dttm> <dbl> <dbl>#> 1 NK630 2017-08-03 17:45:00 2017-08-03 21:00:00 140 194#> 2 NK630 2017-08-03 17:45:00 2017-08-03 21:00:00 140 194#> carrier tailnum origin dest air_time distance origin_city_name#> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr> #> 1 NK N601NK LAX DEN 107 862 Los Angeles #> 2 NK N639NK ORD LGA 107 733 Chicago #> # … with 10 more variables: origin_state <chr>, dest_city_name <chr>,#> # dest_state <chr>, taxi_out <dbl>, taxi_in <dbl>, carrier_delay <dbl>,#> # weather_delay <dbl>, nas_delay <dbl>, security_delay <dbl>,#> # late_aircraft_delay <dbl>As you can see, we've got two problematic data entries. The flight number NK630 has been scheduled twice at the same departure time. They have identical arrival time, departure delay, arrival delay, and carrier. But they are different in tail number, origin and destination. After doing some research about this flight number and going through the whole database, my decision, a simple decision, is to remove the highlighted entry: the flight from LAX to DEN, bc this flight doesn't operate on this route during that period. If I had more domain knowledge, maybe I could correct this instead of deletion. But the message here is fixing the duplicates.
flights_ts <- flights %>% filter(!dup_lgl) %>% as_tsibble(key = flight_num, index = sched_dep_datetime, regular = FALSE)#> # A tsibble: 5,548,444 x 22 [!] <UTC>#> # Key: flight_num [22,562]#> flight_num sched_dep_datetime sched_arr_datetime dep_delay#> <chr> <dttm> <dttm> <dbl>#> 1 AA1 2017-01-01 08:00:00 2017-01-01 11:42:00 31#> 2 AA1 2017-01-02 08:00:00 2017-01-02 11:42:00 -3#> 3 AA1 2017-01-03 08:00:00 2017-01-03 11:42:00 -6#> 4 AA1 2017-01-04 08:00:00 2017-01-04 11:42:00 -3#> 5 AA1 2017-01-05 08:00:00 2017-01-05 11:42:00 -7#> 6 AA1 2017-01-06 08:00:00 2017-01-06 11:42:00 -3#> # … with 5.548e+06 more rows, and 18 more variables: arr_delay <dbl>,#> # carrier <chr>, tailnum <chr>, origin <chr>, dest <chr>,#> # air_time <dbl>, distance <dbl>, origin_city_name <chr>,#> # origin_state <chr>, dest_city_name <chr>, dest_state <chr>,#> # taxi_out <dbl>, taxi_in <dbl>, carrier_delay <dbl>,#> # weather_delay <dbl>, nas_delay <dbl>, security_delay <dbl>,#> # late_aircraft_delay <dbl>Once we remove the duplicated observation, we are all settled. A tsibble is created.
The printing method tries to give useful information. The exclamation mark highlights the irregularity, and the time zone associated with the index. and we've got 22 thousands flights as observational units in the table.

What I have done so far is going through the tidy stage in order to create the tsibble object. Tsibble complains early when the data involves duplicates, like the flights data. We need to find the duplicates and fix them. We now end up with a properly-defined temporal data.
Tsibble permits time gaps. It is recommended to check time gaps before transformation and modelling. Bc you are likely to encounter errors if gaps in time. Bc it's currently irregular, we don't have gaps in theory.
This is how tsibble provides formal and explicit organisation on how to tidy your temporal data.
2. Tsibble is
a domain specific language in
for wrangling temporal data.
⬢ __ _ __ . ⬡ ⬢ . / /_(_)__/ /_ ___ _____ _______ ___ / __/ / _ / // / |/ / -_) __(_-</ -_)\__/_/\_,_/\_, /|___/\__/_/ /___/\__/ ⬢ . /___/ ⬡ . ⬢Tsibble is not only a data abstraction, but also a DSL for wrangling temporal data.
It tries to follow closely to the spirit of the tidyverse, and those familiar with tidyverse will have less cognitive loads to learning the new semantics.
It extends the existing tidyverse vocabulary to the time domain, and introduces some new verbs for making wrangling easier and more intuitive.
carrier_delay <- flights_ts %>% group_by(carrier) %>% index_by(week = ~ yearweek(.)) %>% # week = yearweek(sched_dep_datetime) summarise_at(vars(contains("delay")), list(~ mean(.)))#> # A tsibble: 636 x 9 [1W]#> # Key: carrier [12]#> carrier week dep_delay arr_delay carrier_delay#> <chr> <week> <dbl> <dbl> <dbl>#> 1 AA 2016 W52 13.5 8.91 NA#> 2 AA 2017 W01 15.2 14.4 NA#> 3 AA 2017 W02 8.06 3.64 NA#> 4 AA 2017 W03 4.89 0.237 NA#> 5 AA 2017 W04 2.53 -3.25 NA#> 6 AA 2017 W05 1.90 -4.43 NA#> # … with 630 more rows, and 4 more variables:#> # weather_delay <dbl>, nas_delay <dbl>,#> # security_delay <dbl>, late_aircraft_delay <dbl>Continue with the flights example. It's a great data set, bc it's very fine resolution, detailed information about each individual flight.
But it is overwhelming to explore the data at the individual level straightway. We usually start to look at aggregated data first.
For example, if we're interested in summarising average weekly on-time performance by each carrier, we write the expressive R code just like how I phrased the problem.
You've probably seen group_by() and summarise() before, the only new function here is index_by(), grouping the tsibble index. Since tsibble knows the index, the dot refers to the index variable, which saves some keystrokes. But you can still do.
The index_by() and summarise() combo also helps to regularise the flights data to weekly data. The subjects of interest has also shifted from 22,000 flights to 12 carriers.
Almost all dplyr verbs work with tsibble.
Complain when tsibble cannot hold
carrier_delay %>% select(carrier, dep_delay)#> Selecting index: "week"#> # A tsibble: 636 x 3 [1W]#> # Key: carrier [12]#> carrier dep_delay week#> <chr> <dbl> <week>#> 1 AA 13.5 2016 W52#> 2 AA 15.2 2017 W01#> 3 AA 8.06 2017 W02#> 4 AA 4.89 2017 W03#> 5 AA 2.53 2017 W04#> 6 AA 1.90 2017 W05#> # … with 630 more rowscarrier_delay %>% select_at(vars(contains("delay")))#> The result is not a valid tsibble.#> Do you need `as_tibble()` to work with data frame?But during the transformation stage, if tsibble cannot hold, it will start complaining.
For example, when index is not selected, it will automatically selects the index. When only measured variables are selected, a tsibble is no longer a tsibble, an error pops out, leaving you a hint that you may need to work with data frame instead.
I think it's important to remind users of time context, but keep getting errors may be annoying occasionally.
Tsibble-specific verbs
has_gaps()scan_gaps()count_gaps()fill_gaps()index_by()group_by_key()filter_index()append_row()
has_gaps(carrier_delay)#> # A tibble: 12 x 2#> carrier .gaps#> <chr> <lgl>#> 1 AA FALSE#> 2 AS FALSE#> 3 B6 FALSE#> 4 DL FALSE#> 5 EV FALSE#> 6 F9 FALSE#> 7 HA FALSE#> 8 NK FALSE#> 9 OO FALSE#> 10 UA FALSE#> 11 VX FALSE#> 12 WN FALSEIn addition to index_by(), there are some other domain-specific verbs. You may find this set of gap-aware functions useful for handling implicit gaps in time. As you can see, each carrier has no gaps over weeks.
Some other shortcuts are available for reducing the typing in the time domain.
3. Tsibble rolls with
functional programming.
FP focuses on expressions instead of for-loop statements.
The third aspect of tsibble is adopting FP for rolling windows. Rolling windows are commonly-used techniques for time series applications.
When doing rolling window analysis, we cannot avoid for loops. But tsibble's rolling family keeps users away from for loops. and help concentrate on what you're going to achieve instead of how you're going to achieve.
Map and roll

Map and roll

In terms of functional programming, you'll definitely know base R apply() and purrr map() function. What they all do is to apply a function over each element iteratively.
But for rolling window, they cannot just sleep but have to roll.
x <- 1:12ma_x1 <- double(length = length(x) - 1)for (i in seq_along(ma_x1)) { ma_x1[i] <- mean(x[i:(i + 1)])}ma_x1#> [1] 1.5 2.5 3.5 4.5 5.5 6.5#> [7] 7.5 8.5 9.5 10.5 11.5mm_x2 <- integer(length = length(x) - 2)for (i in seq_along(mm_x2)) { mm_x2[i] <- median(x[i:(i + 2)])}mm_x2#> [1] 2 3 4 5 6 7 8 9 10 11⬅️ For loops
A toy example: computing moving averages for window size 2 and median for 3
In order to compute the mean and median, I have to do a bit of setup for the loop. But the only part we're interested is the action: mean and median.
As you can see, the output is not length-stable, depending on the the choice of window size. This is for loop
x <- 1:12ma_x1 <- double(length = length(x) - 1)for (i in seq_along(ma_x1)) { ma_x1[i] <- mean(x[i:(i + 1)])}ma_x1#> [1] 1.5 2.5 3.5 4.5 5.5 6.5#> [7] 7.5 8.5 9.5 10.5 11.5mm_x2 <- integer(length = length(x) - 2)for (i in seq_along(mm_x2)) { mm_x2[i] <- median(x[i:(i + 2)])}mm_x2#> [1] 2 3 4 5 6 7 8 9 10 11slide_dbl(x, mean, .size = 2)#> [1] NA 1.5 2.5 3.5 4.5 5.5#> [7] 6.5 7.5 8.5 9.5 10.5 11.5slide_int(x, median, .size = 3)#> [1] NA NA 2 3 4 5 6 7 8 9#> [11] 10 11⬆️ Functionals
What I mean by FP? It abstracts away the for-loop, and focus on what you want to do by supplying a function. And it's length-stable and type-stable. The rolling functions in the tsibble package take care of the rest, and users only need to define the functions.
It's a rolling family.
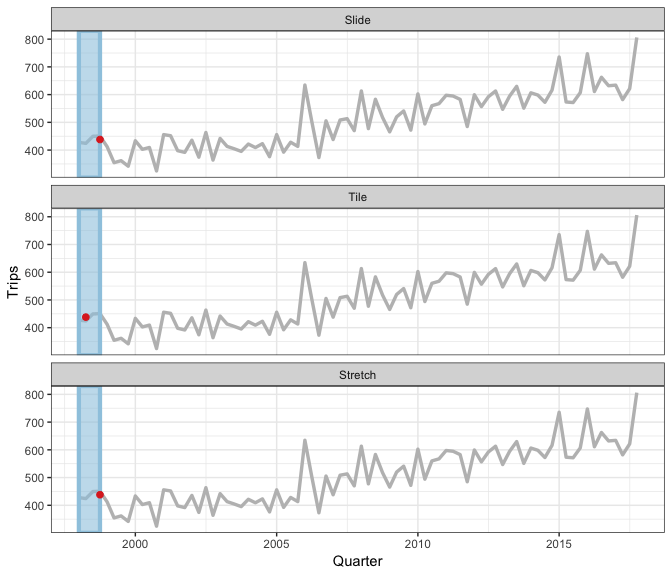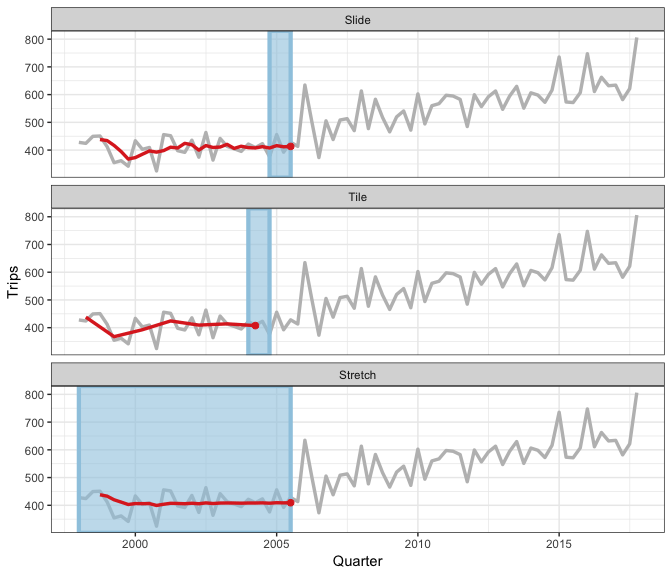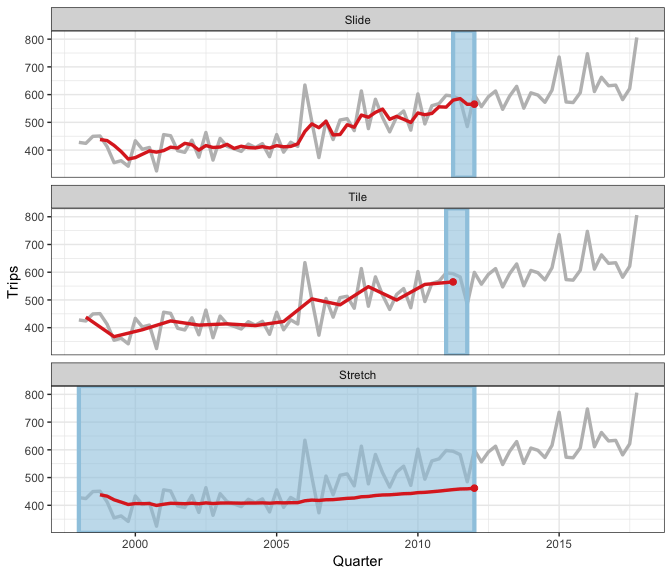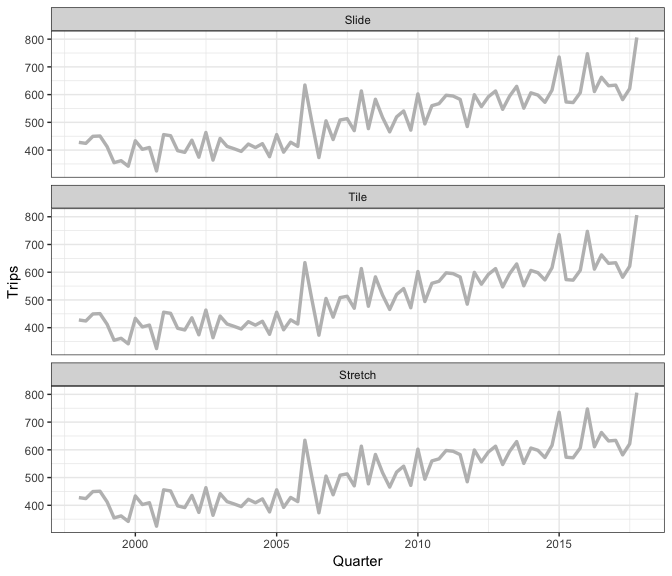
We have a rolling family with 3 variants
- sliding: moves a fixed length window through the data with overlapping
- tiling: moves a fixed length window through the data w/o overlapping
- stretching: fix an initial window and expand to include more observations.
The animation shows three different rolling averages.
They take an arbitrary function: simple complex
They can also run in parallel.
summarise()
Tsibble provides
fundamental data infrastructure.
Lemme briefly summarise the tsibble package.
Tsibble provides a uniform and standardized temporal data structure for downstream analytic tasks. You can easily transform via dplyr and tsibble, visualise with ggplot2, and do modeling with other supporting packages.

tidyverts.org
If you want to take tsibble further for forecasting and high-dimensional analysis, please check out the rest of tidyverts packages that support the tsibble structure.
The fable package is replacing the forecast package. The fasster models time series with multiple seasonality. The feasts package computes a number of time series features and provides many graphics.
We have already started teaching this set of new tools at Monash Uni this year. It actually making both teaching and learning ts much easier.
If you'd like to get some of those stickers, please see me after the talk.
Joint work
 Di Cook
Di Cook
 Rob J Hyndman
Rob J Hyndman
 Mitchell O'Hara‑Wild
Mitchell O'Hara‑Wild

